
Kubernetes PV/PVC 性能比较
Kubernetes PV/PVC 性能比较
如果正在运行Kubernetes,则可能会使用或想要使用卷进行块存储通过动态配置。最大的难题是为的集群选择正确的存储技术。没有简单的答案或单一测试,它可以告诉什么是市场上最好的技术。实际上,这很大程度上取决于要运行的工作负载的类型。对于裸机集群,与公共云托管的k8s集群相比,需要选择正确的选项,并将其集成在自己的硬件上。由AKS,EKS或GKE提供的由公有云管理的k8s带有块存储开箱即用,但这并不意味着它是最佳选择。在许多情况下,默认公共云存储类的故障转移时间花费的时间太长。例如,在附加了Pod的Pod的AWS EBS中测试失败的VM超过5分钟在另一个节点上重新联机。因此,像Portworx或OpenEBS这样的云原生存储正在尝试解决此类问题。
我的目标是采用Kubernetes可用的最常见的存储解决方案,并准备基本的性能比较。使用以下后端在Azure AKS上执行所有测试:
AKS 原生存储类 (native) - Azure native premium
AWS 云硬盘 (pass through)—带有附加的Azure托管磁盘的A ...
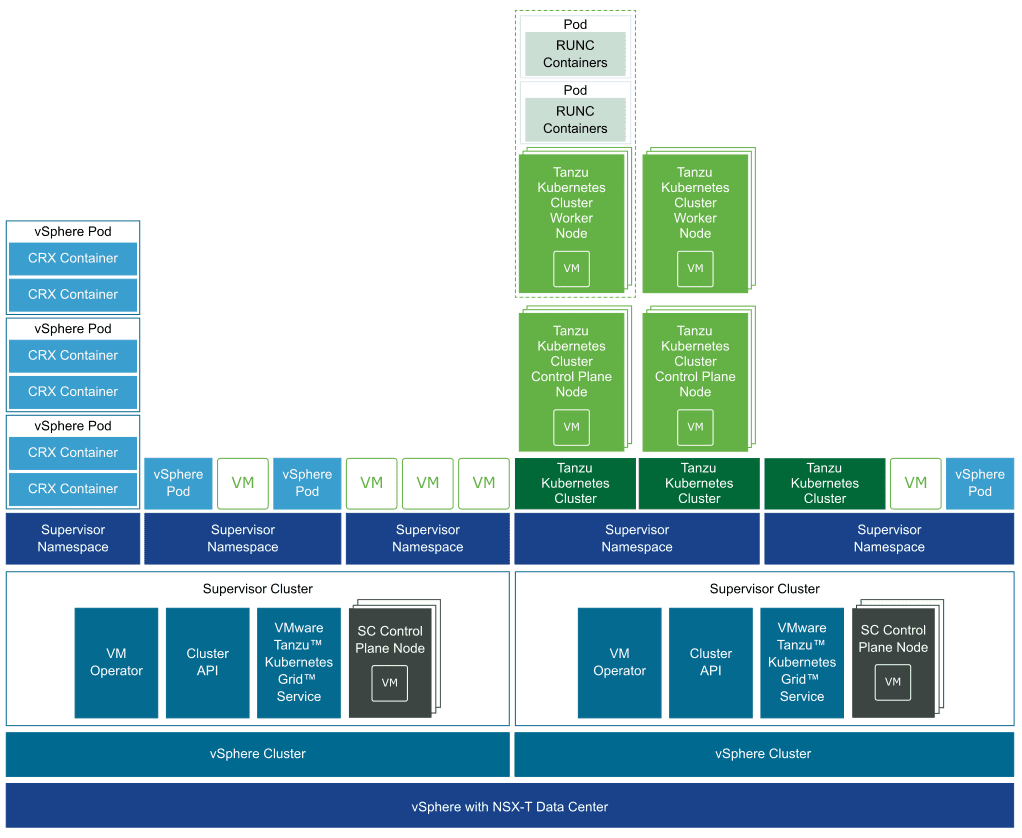
手把手教程 -- 在NSX-T 3.0 VDS上部署vSphere 7 with kubernetes和Tanzu群集
在NSX-T 3.0 VDS上安装带有Kubernetes的Tanzu vSphere 7第1部分:概述,设计,网络拓扑,使用的硬件欢迎关注LLYCLOUD VCTSC,好文不断
资源下载
VMware 资源大全下载
开始:将会有很多人通过Kubernetes撰写有关vSphere 7的博客,可能会想为什么我要这么做。因此,对于我的博客,希望我将提供以下更多详细信息
网络需求。我确定许多VMware同事,客户,合作伙伴将进行评估,并且并不是每个人都熟悉网络,因此希望该博客可以使与网络柜台部分进行有意义的讨论,或者只是让自己了解什么是网络。网络组件或所需的路由。例如,将需要多少个物理NIC?如果是POC环境,我可以使用单个NIC吗?答案是肯定的,并且这样做有些复杂,我将解释为此需要做些什么。
vCenter或NSX-T Managers VM位置。通常,对于生产设计,我们建议将vCenter和NSX-T Manager放在单独的管理群集中。对于基于VVD的VMware验证设计(VVD)和VMware Cloud Foundation(VCF),建议使用此功能。只 ...

重磅首发!全网最全!VMware 资源下载
重磅首发!全网最全!VMware 资源下载
文件目录
名称
版本
文件描述
更新时间
NSX-T Data Center
2.5.1
网络虚拟化
3.0.0
3.0.1
9 July 2020
3.0.1.1
28 July 2020
Nested ESXi OVA
7.0
嵌套虚拟机
VMware Cloud Foundation
4.0.0
云基础设施
VMware Horizon Enterprise
7.7
桌面虚拟化
7.8
7.11
7.12
VMware Identity Manager
3.3.2
统一认证组件
VMware Site Recovery Manager
8.2
备份容灾组件
8.3
VMware vCloud Availability Appliance for Cloud Providers
3.x
4.0
9 July 2020
VMware vCloud Director
10.1.0
云管理
10.1.1
9 ...

Kubernetes Services 负载平衡和反向代理
Kubernetes Services 负载平衡和反向代理在这篇文章中,我将讨论一个主题,任何K8新手一旦了解了基本概念,便会开始考虑。如何将K8s集群中部署的Services暴露给外部流量?我在帖子中使用的内容和一些图表来自我在WSO2进行的一次内部技术演讲。
让我们定义一些术语!在继续进行实际讨论之前,让我们定义一些术语并达成一致,因为如果不首先定义为特定术语,它们可能会与每次使用混淆。让我们定义一个示例部署,并在稍后的讨论中引用该示例部署的各个部分。
有基本的了解Pods,Services,以及的使用Services类型在K8S预计本文中讨论的主题。
K8s集群—在其中创建和维护Pod,Services和其他K8s构造的边界。这包括K8s主节点和调度实际Pod的节点。
Node(大写N)—这些是所有Pod,Volumes和其他计算构造都将在其中生成的K8s节点。它们不受K8的管理,并且位于由IaaS提供程序分配给它们的专用网络内生成虚拟机时。
Node专用网络— K8s节点位于Cloud Service Provider中的专用网络中(例如:AWS VPC)。对于示例部署, ...

升级 NSX-T 3.0.2
随着NSX-T 3.0.2的发布,我已经准备好在当前的NSX-T环境中进行升级。NSX-T 3.0.2具有许多出色的新功能,使其从以前的NSX-T安装中非常值得升级。在这里查看我们的文章,了解NSX-T 3.0.2中包含的新功能,使其值得从以前的版本进行升级。升级NSX-T环境的过程是什么样的?让我们逐步了解如何将NSX-T 3.0升级到3.0.2,并了解此过程涉及什么。
NSX-T升级过程概述VMware已发布检查清单,以在升级NSX-T环境之前进行检查。这包括检查环境的各个方面。可能想知道升级NSX-T会带来什么样的影响。
这完全取决于必须在基础架构中升级的组件数量。升级NSX-T数据中心的过程涉及以下操作顺序:
NSX Edge cluster > host > control plane
根据所使用的NSX-T版本,该过程可能看起来略有不同。
作为NSX-T升级过程的概述,可以分多个步骤进行处理。根据所使用的NSX-T版本,此过程可能看起来略有不同。
准备升级文件
升级edge
配置和升级host
升级NSX Edge群集
升级 NSX控制器群集
升级管理节点 ...

嵌套ESXi Homelab 实验环境
嵌套ESXi Homelab 实验环境
拥有实验室环境的许多人每天都在学习VMware vSphere,并且可能已经在使用VMware vSphere产品。我一直是实验室环境的拥护者。即使有许多吹捧者迁移到云计算之类的地方,仍然始终需要真正了解数据中心幕后情况的人们。拥有实验室环境是构建,破坏,故障排除,升级以及最重要的是学习的好方法。要学习VMware vSphere,拥有嵌套的ESXi实验室是学习VMware vSphere虚拟机管理程序基础知识的好方法,而又不会花费很多物理实验室主机的资金。让我们看一下嵌套ESXi实验室构建网络和硬件,以了解如何从头开始成功构建嵌套ESXi实验室。
什么是嵌套虚拟化?嵌套虚拟化基本上就是您在另一个虚拟机监控程序“之上”运行虚拟机监控程序的地方。想想电影《盗梦空间》。您可以在另一台物理ESXi虚拟机管理程序主机上将ESXi虚拟机管理程序作为VM运行。现在,您可能想知道为什么要这样做。答案很简单–实验室。
当将嵌套ESXi实验室作为运行在物理ESXi虚拟机管理程序主机上的VM运行时,您将拥有在vSphere内部运行的VM通常具有的所有优势。这包括能够 ...

VMware vSphere 7 Update 1 GA免费下载
VMware vSphere 7 Update 1 免费下载对于所有渴望等待vSphere 7 Update 1可用性的vSphere管理员来说,今天是个好消息。vSphere7 U1发行版包含许多出色的功能和增强功能,非常值得从以前的任何vSphere版本进行升级,但包括甚至是vSphere 7.0“扁平化”。在本文中,我们将介绍可下载的VMware vSphere 7 Update 1 GA,并了解其功能和特性以及下载链接。
vSphere 7 Update 1下载链接可以从以下下载链接下载新的vSphere 7 Update 1 GA版本:
vmv.re/vmrd
发布VMware vSphere 7 Update 1 GA可供下载
VMware vSAN 7 Update 1功能和改进VMware会继续听取客户关于vSAN及其相关产品中希望看到的特性的信息。让我们看一下最新版本的VMware vSAN 7 Update 1中发现的以下改进和功能。
VMware vSAN 7 Update 1功能和改进
vSAN 7 Update 1包含以下改进,特性和功能,它们是对先前版本 ...

VMware Horizon 8升级Connection Servers
VMware Horizon 8升级Connection ServersVMware的 Horizon 8今天已经登陆一般可用性%的博客文章来自VMware 在这里。VMware Horizon 8代表了VMware Horizon产品的发展。实际上,VMware现在将产品更名为“ VMware Horizon”。此后的版本将采用VMware Horizon YYMM的形式。VMware Horizon 8也称为“ VMware Horizon 2006”。但是,我猜想VMware会保留Horizon 8品牌,因为这是每个人对下一个版本的期望。我想在家庭实验室中获得新版本。我决定从我的VMware Horizon Connection服务器开始。在本文中,我们将介绍VMware Horizon 8升级Connection Servers,以了解如何升级到Horizon 2006。
升级到VMware Horizon 8Connection Servers之前在此版本中,肯定有一些事情要注意。这些是以下内容:
VMware Horizon 8 2006版本不建议使用View Compo ...

vCenter Server 7.0 优化技巧
在vSphere 7.0中,基于Windows的vCenter Server终于消失了。是时候前进并与基于Linux的Photon OS取得联系了。使用vCenter Server Appliance 7.0时,以下提示和技巧可能会派上用场:
启用SSH
使用SCP / SFTP进行文件传输
公钥认证
禁用或增加Shell会话超时
密码过期
重置vCenter Server Appliance 6.7根密码
创建备份作业
删除证书警告(根CA)
安装其他软件
VMware Datacenter CLI(DCLI)
运行Docker容器
启用SSH要对vCenter和ESXi主机进行故障排除,SSH是必不可少的。默认情况下,将禁用对vCenter Server Appliance的SSH访问,但可以在部署向导中将其激活。在已部署vCenter之后,可以在“设备管理”中启用SSH。
设备管理(https:// [VCENTER]:5480 /)>访问>编辑>启用SSH登录
使用SSH连接到vCenter后,您会看到专有的设备外壳。要打开功能齐全的Bash,只需键入“ ...

VMware vRealize Network Insight 5.2 部署
如果您拥有基于VMware NSX的软件定义的网络基础架构,则您将拥有功能强大的平台,可以为您的环境提供下一代网络。但是,如果没有合适的工具,那么了解您的流量如何流动,对现在“抽象的”网络层的来龙去脉具有灵活性就很难了。VMware vRealize Network Insight是用于管理软件定义的网络和安全策略的首选工具。在本文中,我们将查看VMware vRealize Network Insight安装指南,以了解如何在您的环境中启动该解决方案。
VMware vRealize Network Insight可以做什么?在部署软件定义的基础架构并计划微细分策略时,vRealize Network Insight有助于消除网络实际运行情况的猜测。您不再需要猜测特定应用程序会发生什么网络流量。
它还可以为您的虚拟和物理网络提供可见性。总体而言,它有助于管理,排除故障和保护网络安全。
vRNI的功能包括:
计划微细分的能力
对本地,云或混合部署中的安全性进行故障排除
降低风险
减少连接问题的平均解决时间(MTR)
消除网络瓶颈
跨NSX经理扩展
确保合规
vRealize Net ...

NSX-v与NSX-T -- 全面对比
NSX-v与NSX-T – 全面对比虚拟化对数据中心的构建方式进行了革命性的改变。大多数现代数据中心使用硬件虚拟化并将物理服务器部署为虚拟机管理程序,以在所述服务器上运行虚拟机。这种方法提高了数据中心的可伸缩性,灵活性和成本效率。VMware是虚拟化市场上的佼佼者之一,其产品在IT行业中备受推崇,其VMware ESXi Hypervisor和VMware vCenter是VMware vSphere虚拟化解决方案的知名组件。
网络是每个数据中心(包括虚拟化数据中心)的重要组成部分,如果您需要大型网络和虚拟化数据中心的复杂网络配置,请考虑使用软件定义网络(SDN)。软件定义的网络是一种旨在使网络敏捷灵活的体系结构。SDN的目标是通过使企业和服务提供商能够快速响应不断变化的业务需求来改善网络控制。VMware关心客户,并提供VMware NSX解决方案来构建软件定义的网络。今天的博客文章涵盖了VMware NSX,并探讨了VMware NSX-v和VMware NSX-T之间的区别。
什么是VMware NSX?如何使用?VMware NSX是一种网络虚拟化解决方案,可让您在虚拟化数据中 ...
VMware NSX-T 7层防火墙配置
VMware NSX-T 7层防火墙配置从VMware NSX-T 2.4开始,VMware引入了NSX功能,可以查明应用程序身份,FQDN和URL白名单,并提供基于身份的防火墙。自2.4版本以来,NSX-T的所有这些功能使该平台的功能和特性达到了新的高度。借助新的第7层应用程序标识,的组织的微细分目标变得更加容易实现,并且实际上可以实现上下文感知的微细分。在本文中,我们将介绍NSX 7层防火墙功能,并更好地概述所提供的功能。
什么是NSX上下文感知防火墙?VMware能够借助NSX上下文感知防火墙彻底改变防火墙的安全性世界。NSX可以作为虚拟机管理程序内核的一部分并“看到”即将到来的流量,而不是像传统防火墙那样使用IP子网和安全区域的非常静态的结构,而是可以使用它具有可见性的非常丰富的知识。和那里的工作量。
这使得NSX本质上是非常动态的。使用某种类型的网络流量的应用程序ID,可以将其视为指纹。无论的网络中遇到哪种类型的流量,都可以有效地识别该端口并将规则应用于该类型的流量。
有了上下文感知防火墙的想法,NSX现在可以使用基于特定特征,操作系统,应用程序标识等的构造。它也可以与基于身 ...
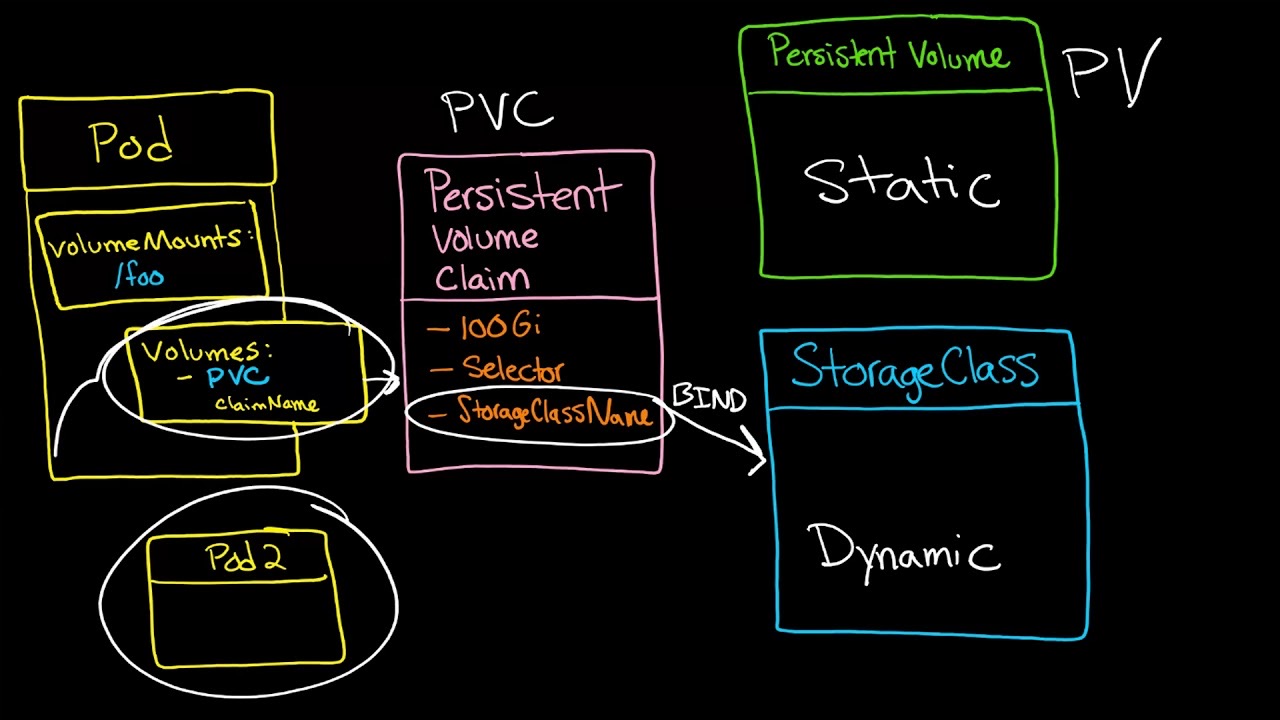
Defalut Storage Class 管理 vSphere 7 with k8s
Defalut Storage Class 管理 vSphere 7 with k8s
vSphere Pod Service defalut Storage Class 配置通过此配置,可以在带有Kubernetes环境的vSphere 7中成功创建持久卷(PV)并通过持久卷声明(PVC)附加它们。
简要介绍一下什么是Cloud Native Storage。Cloud Native Storage是为状态应用程序提供全面数据管理的解决方案。
使用 Cloud Native Storage时,您可以创建能够在重启和中断中幸存的容器化状态应用程序。有状态的容器利用vSphere提供的存储空间,同时使用诸如标准卷,持久卷和动态配置之类的原语。
使用 Cloud Native Storage,您可以创建独立于虚拟机和容器生命周期的持久性容器卷。vSphere存储支持卷,您可以直接在卷上设置存储策略。创建卷后,可以在vSphere Client中查看它们及其支持的虚拟磁盘 ,并监视其存储策略合规性。
在我的环境中进行更改之前,所有有状态的Pod以前都一直处于“待处理”状态。
Pod des ...
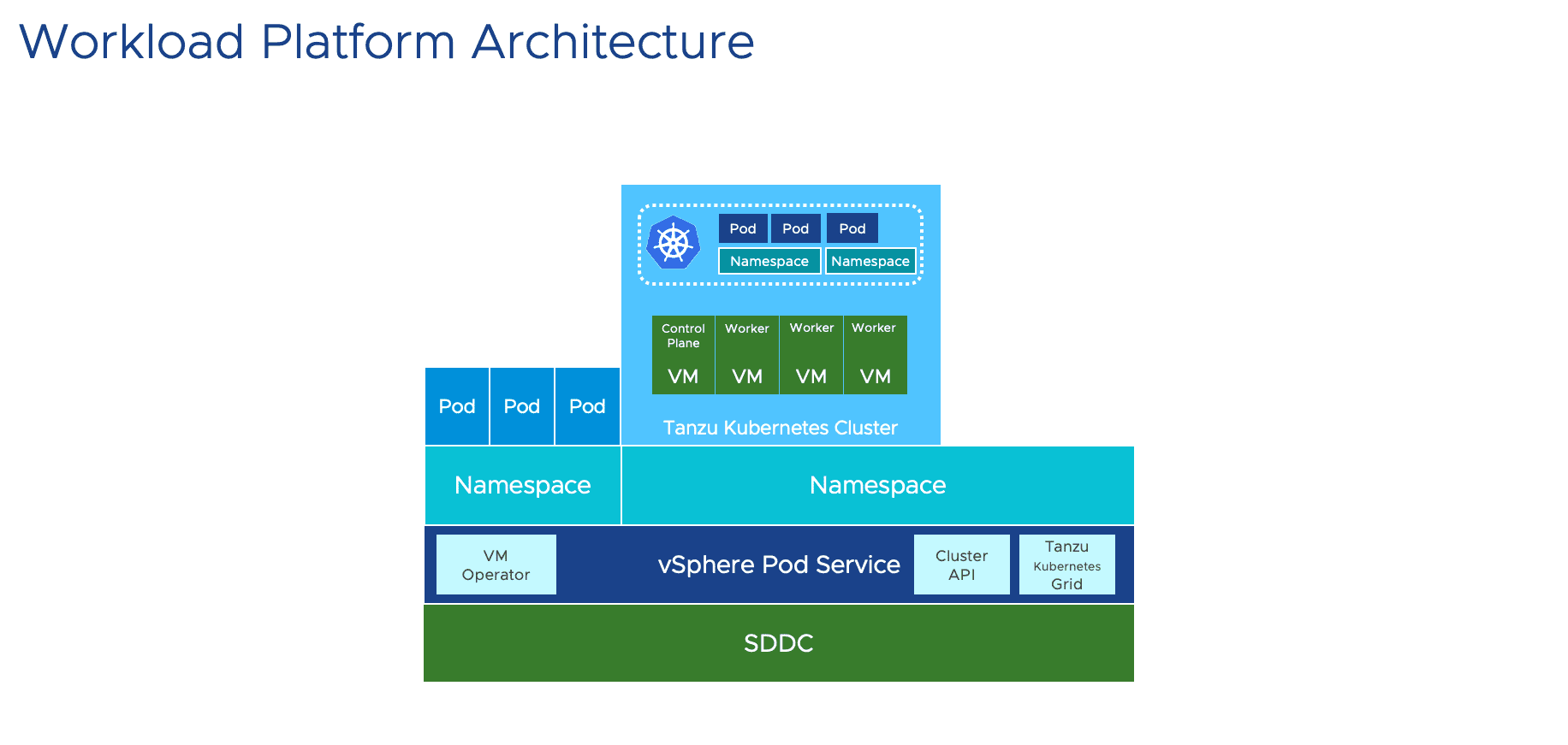
对手动vSphere + k8s说不!全自动化Tanzu kubernetes on vSphere 教程附视频
对手动vSphere + k8s说不!全自动化kubernetes on vSphere 教程附视频
视频
/* 这个规则规定了iframe父元素容器的尺寸,16:9的近似值为56%*/
.selfadapting-video {
position: relative;
width: 100%;
height: 0;
padding-bottom: 56%; /* 高度应该是宽度的56% */
}
/* 设定iframe的宽度和高度,让iframe占满整个父元素容器 */
.selfadapting-video iframe {
position: absolute;
width: 100%;
height: 100%;
left: 0;
top: 0;
}
环境准备欢迎关注LLYCLOUD VCTSC,加群一起讨论VMware kubernetes!
vSphere先决条件
vSphere 6.7 Update 3环境
vSphere Mana ...
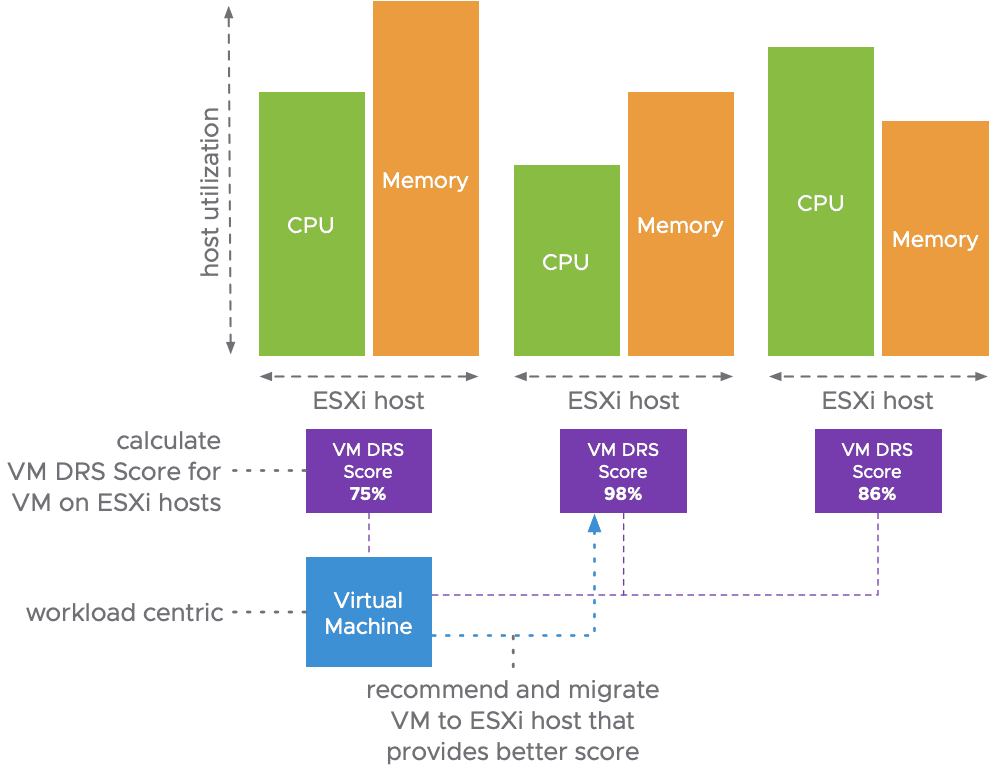
vSphere 7 – VM RDS 新均衡算法
在vSphere 7中,VMware发布了大大改进的分布式资源调度程序(DRS)逻辑。VMware收到了来自客户的大量请求,以提供有关VM DRS分数的更多信息。这篇博客文章详细介绍了新的DRS算法,重点是VM DRS分数。
DRS致力于确保集群中的所有工作负载都令人满意。“快乐”意味着工作负载可以消耗他们有权使用的资源。这取决于许多因素,例如群集大小,ESXi主机利用率,工作负载特征和虚拟机(VM)配置,重点是计算(vCPU / Memory)和网络资源。DRS通过计算和执行集群中的智能工作负载布置以及工作负载平衡来实现VM的幸福。
在以前的vSphere版本中,DRS使用群集范围内的标准偏差模型度量来优化工作负载的“幸福感”,如上图所示。从本质上讲,这意味着DRS专注于ESXi主机利用率基准,这是可以使用DRS迁移阈值配置的特定阈值范围。重新升级的DRS逻辑与其前身采用的方法大不相同。它通过测量VM幸福度来优化VM幸福度!
欢迎关注LLYCLOUD VCTSC,好文不断
VM DRS分数在vSphere 7中,DRS通过计算每个VM的VM DRS分数来衡量VM的满意度。每分钟 ...
Announcement


